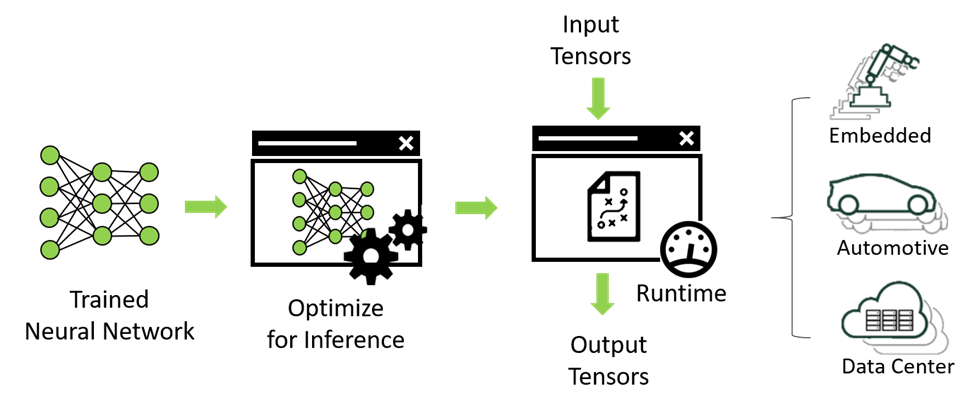
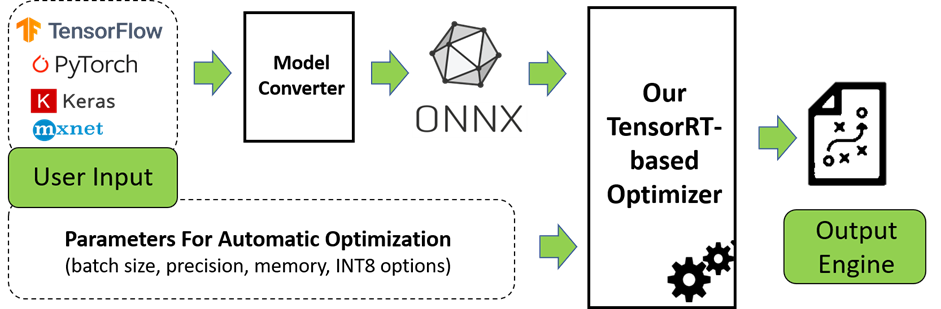
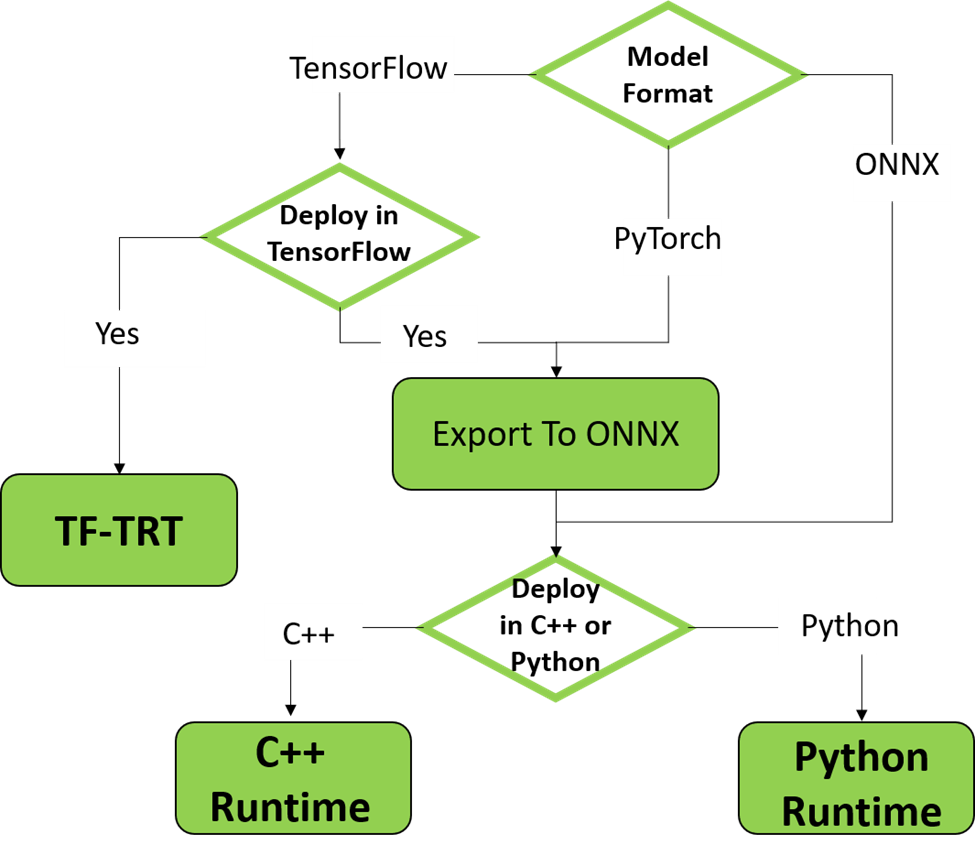
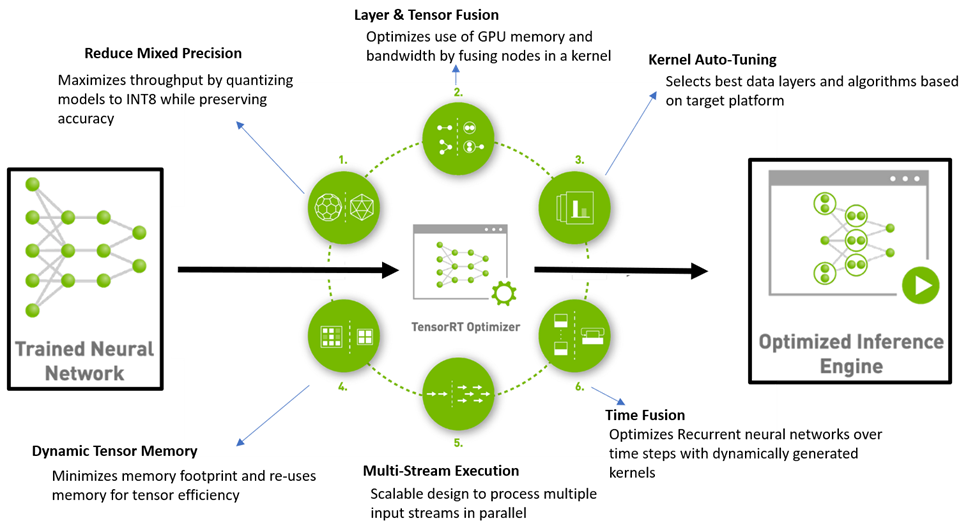
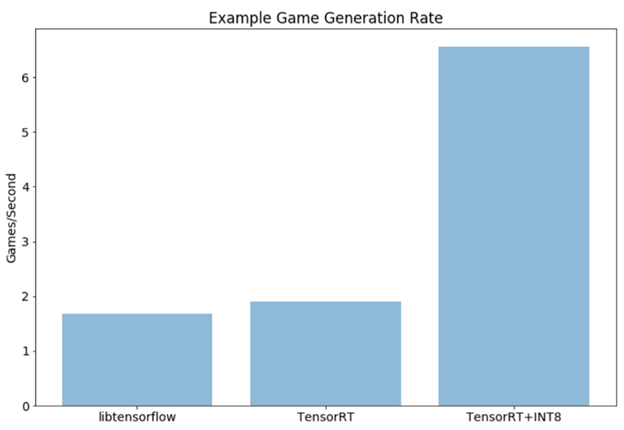
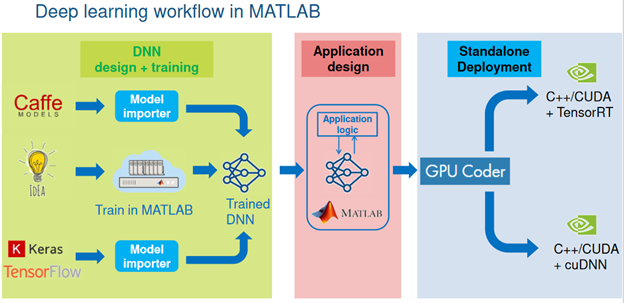
The final stage of deep-learning development process is deploying your model at a specific target platform. In real-world applications, the deployed model is required to execute inferences in realtime or higher speed, and the target platform might be very resource-limited, for example, embedded system such as automotive or robot platforms. However, the trained model, in general, does not satisfy the performance requirement in production. In the worst case, the model might not be run on the target platform because of memory limitation of the target system. So, a proper optimization of the trained model to improve performance is essential for deployment.