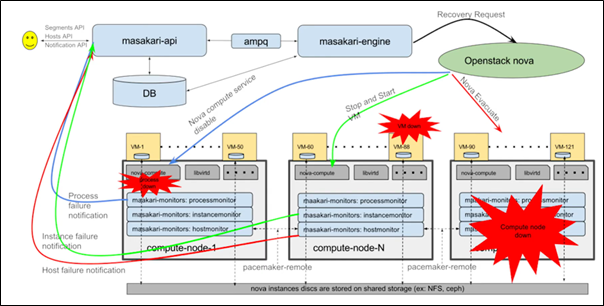
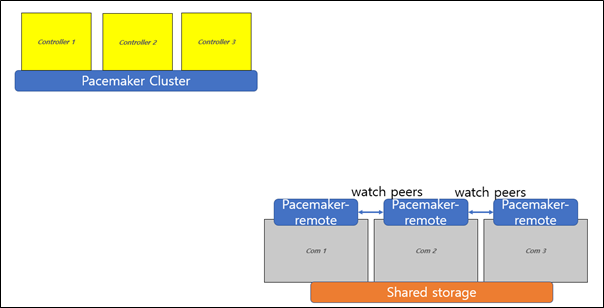
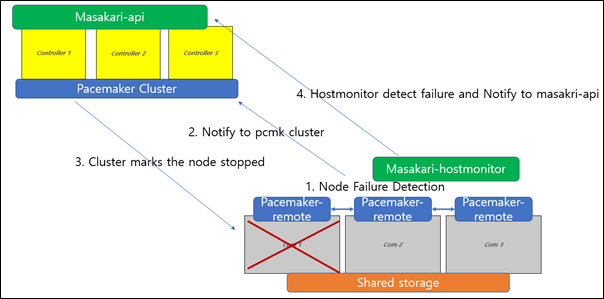
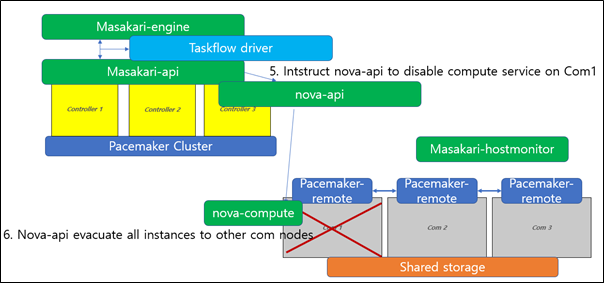
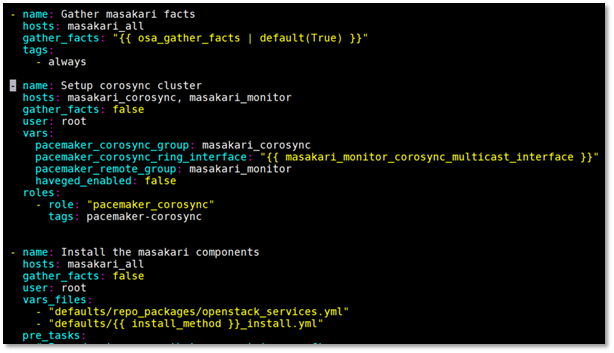
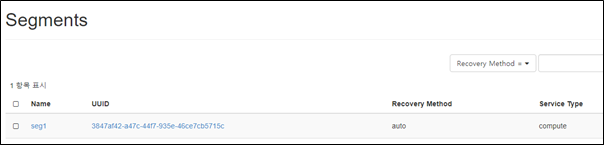
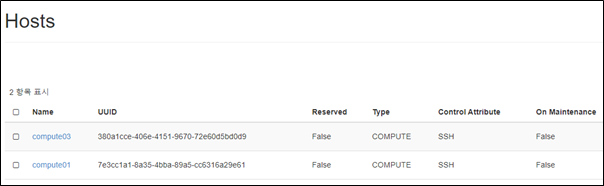
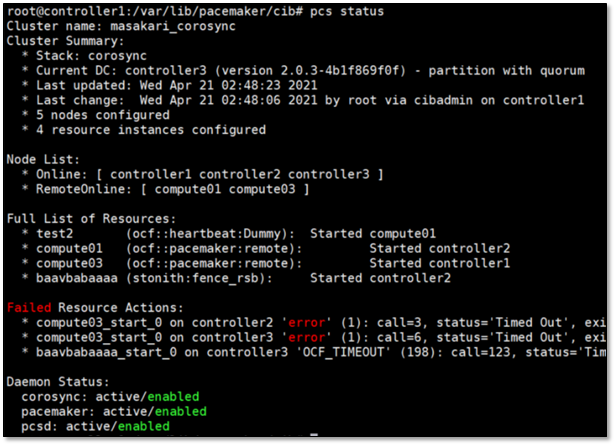
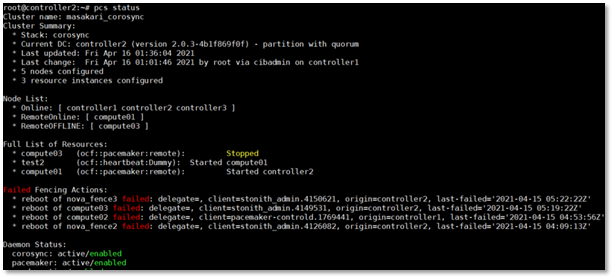
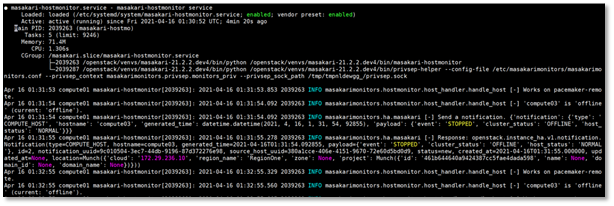
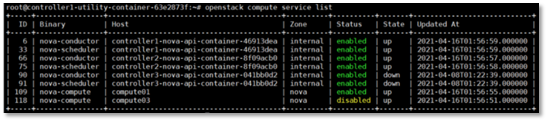
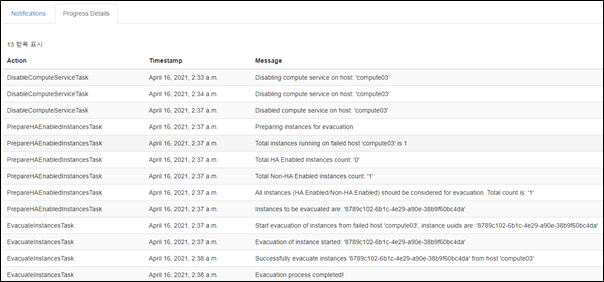
This is what original masakari project deploys with. Uptill openstack-ansible Ussuri release(21.2.5), masakari ships masakari-api, masakari-engine, masakari-monitors, and the DB configuration scripts. Only with these component, masakari cannot function properly. For example, when a compute node fails, the maskari-hostmonitor need to notify the event to the masakari-api. Then, masakari api can call the rest of procedure for evacuation. However, without pacemaker involved, the masakri-hostmonitor never aware of the failing host.