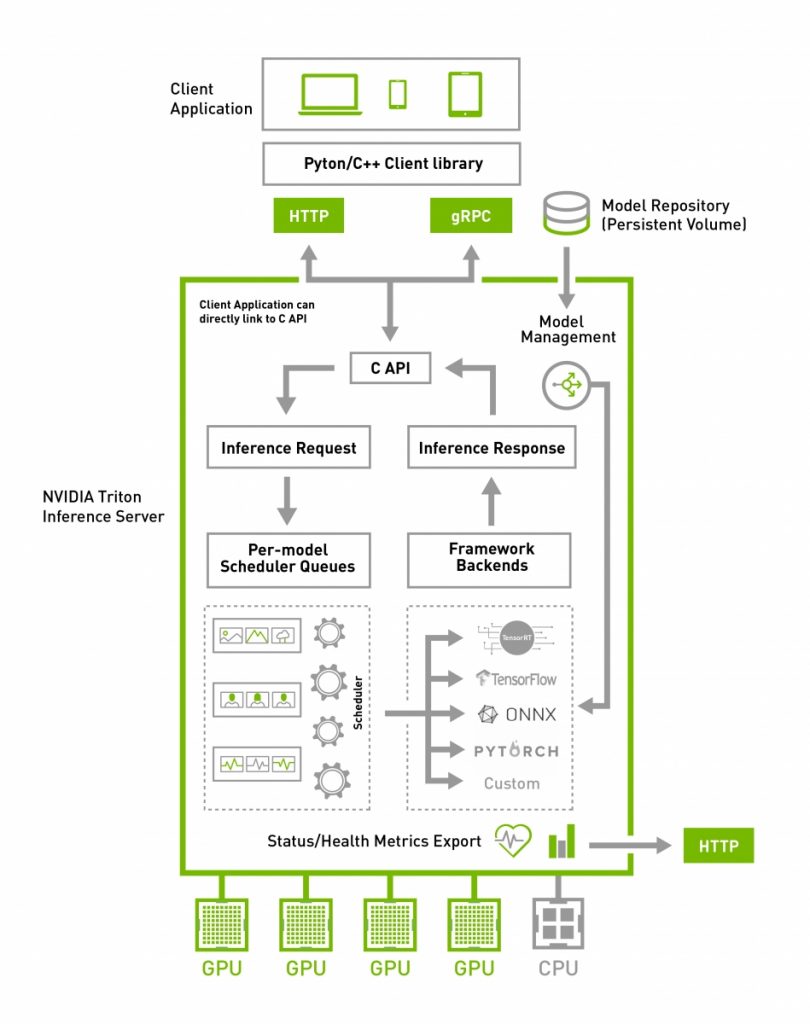
NVIDIA® Triton Inference Server (formerly NVIDIA TensorRT Inference Server) simplifies the deployment of AI models at scale in production. It is an open source inference serving software that lets teams deploy trained AI models from any framework (TensorFlow, TensorRT, PyTorch, ONNX Runtime, or a custom framework), from local storage or Google Cloud Platform or AWS S3 on any GPU- or CPU-based infrastructure (cloud, data center, or edge).
– nvidia.com